TL;DR: I built OpenCandle, a financial research agent, to learn what helps when agents build software that itself uses agents. I was able to move fast when the rails were clear: specs, evals, traces, UI references, and review loops. However, when I let agents make core product decisions, they mostly made the system bigger without adding much meaningful value.
This post is partly inspired by Mario Zechner’s writeup on Pi, What I learned building an opinionated and minimal coding agent. Mario built Pi because he wanted a coding agent he could understand, inspect, and control. I had the opposite starting point: I based OpenCandle on Pi as the agent substrate, and I wanted to see how far I could push it into a domain-specific agent for finance.
This is more of a build log: what worked, what did not, and what I would do again.
Why build a financial agent at all?
I wanted a financial research agent that could do better than a generic ChatGPT, Claude, or Gemini thread.
You can ask a general model about a stock, an options chain, a portfolio, or a macro question, and it will usually produce a clean paragraph. The problem is that the paragraph often arrives before the system has earned the right to have an opinion. It may sound reasonable. It may even be directionally right. But it often skips the work a human analyst would do first: check the data, notice what is missing, and separate evidence from judgment.
The loop I wanted was:
understand the question
-> pick an investigation path
-> gather market evidence by invoking the right tools
-> synthesize after the evidence existsThe product spine was simple: help the user investigate a financial question with better evidence.
Why build it on Pi?
Pi gave me the low-level agent loop I wanted without forcing a giant product surface on me.
Mario’s post describes Pi as a deliberately small, inspectable coding-agent stack: provider abstraction, agent core, TUI, session handling, tool calling, streaming, and enough UI to work without hiding the machine. That mattered for this project because finance is a bad place for opaque agent behavior.
If a finance agent gives a bad answer, I need to know why:
- Did it route the question wrong?
- Did it call the wrong tool?
- Did a provider return stale or empty data?
- Did the model ignore a data gap?
- Did the final answer overstate confidence?
- Did the UI hide the important caveat?
A generic chat wrapper would have made the first prototype easy and the later debugging miserable. Pi made it easier to treat the finance layer as an extension: tools, prompts, workflows, state, GUI, traces, and evals on top of a core loop I could inspect.
What the build taught me
The finance use case, for me, was a great way to get my hands dirty with the agent-building process. It had enough real complexity to expose weak spots: provider setup, missing or stale data, routing ambiguity, workflow state, GUI presentation, and evals that needed to judge usefulness.
The real work was not making the model sound more financial. It was deciding which layer owned each responsibility:
- tools fetch and normalize evidence
- workflows preserve the investigation path
- prompts synthesize after evidence exists
- UI makes gaps and caveats visible
- evals decide whether a change helped or hurt
Whenever those boundaries were explicit, agents were productive. Whenever they were fuzzy, agents added surface area.
The same was true for answer contracts. For each class of question, the answer needed to preserve a contract: what evidence it should cite, what uncertainty it should keep visible, what it should refuse to infer, and what action it should not pretend to recommend. Without that contract, the agent could fetch good data and still produce a weak answer. For example, a current-price answer should cite the provider and timestamp, avoid pretending delayed data is live, and say when the price is unavailable. A portfolio-construction answer should explain assumptions and risk, not present itself as personalized financial advice.
A small routing bug made this concrete. One ambiguous market data request looked like a prompt problem, so an agent tried to fix it by adding more instruction text. The durable fix was a fixture that captured the case, a narrow router change, and an eval proving the route stayed stable. The prompt patch looked cheaper, but it made the system harder to reason about.
Spec-driven development was the biggest unlock
The best process decision was using OpenSpec as the shared planning surface between me and the agents. A Claude or Codex plan usually stops at a certain length, no matter how complex the feature is, so complex behavior cannot be captured up front in a single chat plan.
The useful loop was not “write a giant spec, then code.” It was conversational and incremental:
- Use
/opsx:exploreto go back and forth with an agent until the idea was clear. - Use
/opsx:proposeto put the decision, acceptance criteria, and task breakdown on paper. - Run a review loop with another agent, usually through
acpx, before implementation. - Use
/opsx:applyto make the change against the accepted proposal. For larger OpenSpecs, the/goalcommand in Claude and Codex was useful because it let the agent work through the accepted plan in a more durable way.
In this setup, those /opsx:* commands were repo-local OpenSpec workflows for exploration, proposal writing, and implementation.
That flow mattered because agents are extremely literal. If the task says “fix routing,” an agent may patch a prompt and move on. If the spec says where routing lives, what the acceptance gate is, what observability must exist, and which layer owns the failure, the agent has a much better chance of doing durable work.
Once implemented, I archived the OpenSpec docs with /opsx:archive, which turned them into a log of decisions over time.
Agents need evals, not encouragement
A financial agent needs a way to prove it did the right thing.
Unit tests were table stakes, but they did not answer the important product question: did the agent choose the right investigation path, use relevant tools, disclose gaps, frame risk, and answer the user directly?
So I added several eval layers:
- request-understanding fixtures for routing and extracting the concrete fields a tool or workflow needs
- a TUI harness that lets another agent drive the finance agent like a user
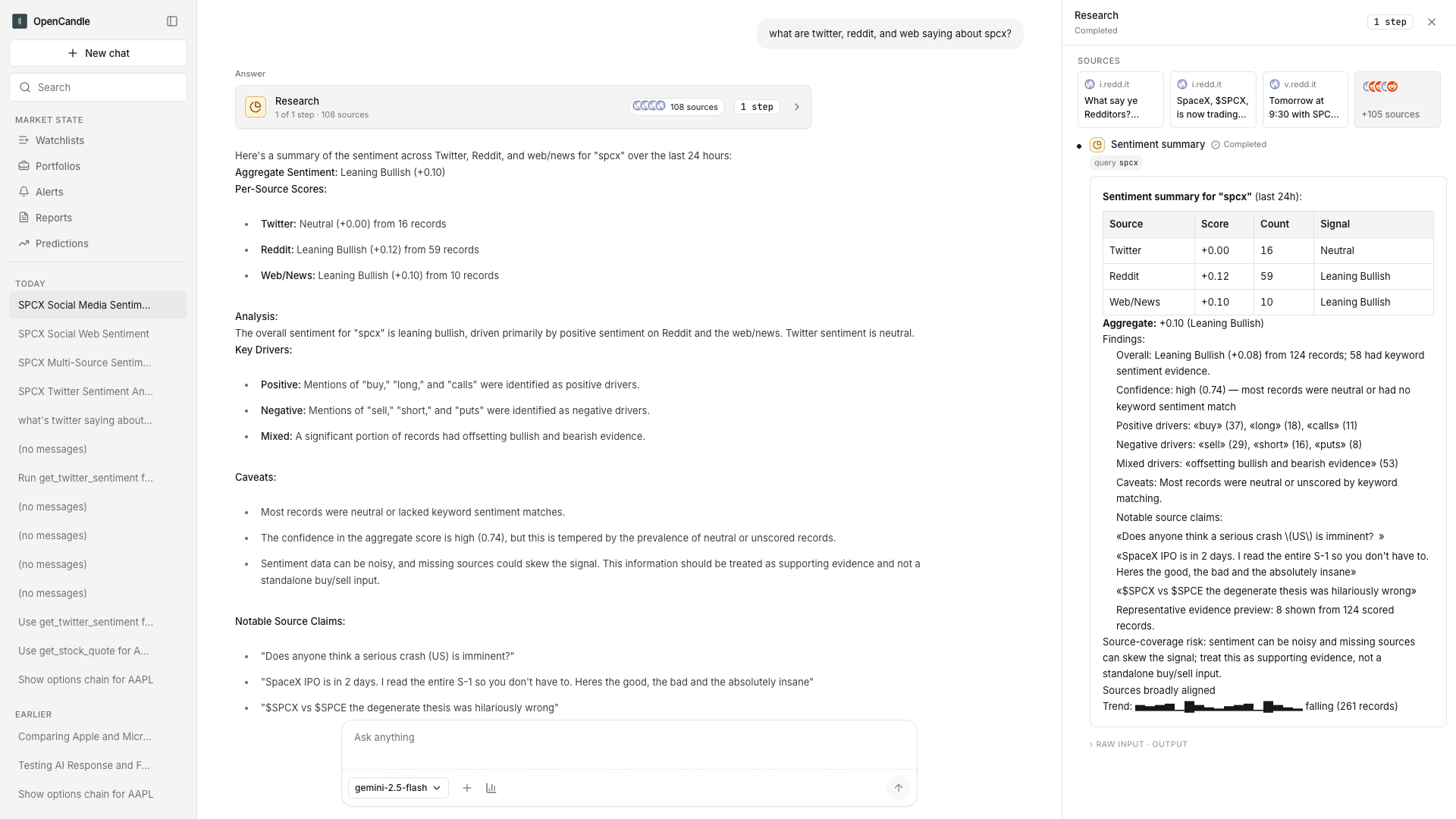
- trace capture for tool calls, tool results, workflow dispatch, custom entries, interactions, final answer, and duration
- product evals over prompts a real user might ask
- competitive finance evals that use
acpxto compare the finance agent with no-tool Claude, Codex, and Gemini baselines - judge reports that classify failures by layer: routing, planning, evidence, tool capability, answer contract, synthesis, or harness
The trace is the important part. If a change makes an answer worse, I do not want to debate whether the prose sounds more polished. I want to know whether the route changed, whether the tool bundle changed, whether the evidence plan changed, and whether the answer stopped carrying the right risk caveat.
Dogfooding tested the whole loop
Dogfooding was not just a source of better prompts. It was the end-to-end check that the agent still worked across both surfaces: the TUI and the browser GUI.
Every meaningful change needed a small dogfood pass. I would run realistic finance questions through the TUI harness, inspect the trace, then exercise the GUI with browser automation to make sure the same behavior was visible and usable in the workbench. The agents had tools for both sides of that loop: a TUI harness for driving the finance agent like a user, and browser automation for checking the GUI.
The prompts were still ordinary user questions:
What is AAPL trading at?
Compare MSFT and GOOGL using price, fundamentals, and sentiment
Show me TSLA puts with Greeks
Build me a balanced $50k portfolio for a 3 year horizon
What is Reddit and news sentiment saying about META?
How should falling rates affect growth stocks over the next year?Dogfooding prompts like this through the system tested if it survived the whole path: routing, tool calls, trace, final answer, and GUI presentation. Sometimes the agent asked for clarification when a reasonable default existed. Sometimes it used the wrong tool. Sometimes it let setup problems, like missing provider keys, dominate the answer instead of presenting them as caveats. Sometimes it fetched useful data and then wrote a generic answer anyway. Sometimes the GUI had the right data but presented it in a way that did not help the user make a decision.
Dogfooding changed the product because it kept pulling the work back to user intent. The useful question was: does OpenCandle take the right investigation path, and can I verify that path end to end?
Review loops beat trusting one agent
I became much more convinced that agents should review each other.
I used acpx to run review loops across agents. If the primary implementation agent was Codex, I would often have Claude review the diff, then send the findings back to Codex to address. The reviewer was not magically objective, but it caught mistakes the first agent had already rationalized.
I also adapted the autoreview idea from OpenClaw’s autoreview skill into a repo-local review helper with a finance-specific checklist:
- block guessed prices, ratios, filings, or option values
- keep synthesis in prompts and analysis layers, not data-fetching tools
- mock providers with fixtures in unit tests
- avoid routing fixes that overfit to a few tickers or benchmark phrases
- require screenshots for PRs that change the GUI
- keep docs and changelog in sync when behavior changes
The checklist mattered because the worst agent mistakes were ownership errors. A policy moved into a prompt when it belonged in a provider. A routing edge case got fixed with a special phrase instead of a fixture. A UI state got added when the product should probably have become simpler.
The review loop kept asking: is this the right layer?
React Doctor made UI work less vibes-based
A browser workbench has a lot of ways to go subtly wrong: stale state, effect loops, inaccessible controls, slow renders, inconsistent setup state, hidden errors. A screenshot review catches some of that. It does not catch all of it.
React Doctor helped because it gave the agent review loop a structured artifact. For React changes, the review helper could run React Doctor against changed files and fail on errors. That turned “this component feels messy” into something more concrete: state, effects, performance, architecture, security, accessibility.
It did not replace using the browser. It made the first pass less subjective.
UI references helped more than UI prompts
Two UI references helped a lot:
- trendy-design/llmchat
- component styling and visual direction from efferd.com
This is a simple lesson, but it changed the speed of the project. If you want agents to build UI, give them a real reference.
“Make it polished” gets you generic SaaS gradients and cards. “Use this chat layout as a structural reference, keep our finance cards denser, and borrow this component feel” gives the agent something to translate.
Agents are strong translators when the source and target are clear. They are much weaker at taste from first principles.
Phone coding actually mattered
The surprising lesson from phone coding was that agent workflows need to be steerable in small, reviewable chunks. I would estimate that about 60% of the prompts I issued for OpenCandle came from my phone.
I was busy with a newborn. I did not always have a clean two-hour desk block. But I did have small gaps: holding the baby, waiting somewhere, sitting with one hand free. Agents made those gaps useful.
The rails I had set up meant I could give a rough thought and let the agent figure out the next concrete step. A vague idea could become an OpenSpec exploration, a small proposal, a fixture, or a review request instead of disappearing until I was back at my desk.
The mobile tooling mattered too. In my setup, the Codex and Claude mobile apps could connect back to the desktop session, so the real repo and dev server stayed in one place while I steered from my phone. I also used t3.codes heavily for quick side conversations, drafts, and second opinions.
The phone became a steering device. I could keep the project warm while life was fragmented.
What went wrong: agents make code feel too cheap
The biggest downside is that agents make adding code feel cheap.
Cheap code is dangerous. Every new feature adds maintenance load, docs, tests, UI states, setup flows, provider failure modes, and future explanations. Agents do not feel that weight unless the process makes them feel it.
This finance agent accumulated breadth quickly: tools, providers, workflows, GUI panels, eval runners, review helpers, docs, specs. Some of that breadth is real product value. Some of it needed consolidation later.
If I were doing it again, every feature request would include a deletion question:
- can this use an existing provider wrapper?
- does this belong in a tool, router, workflow, UI, or answer contract?
- what can be deleted if this lands?
- what eval proves this matters?
- what real user prompt gets better?
If you do not ask those questions, the codebase grows in the direction of the agent’s convenience.
What went wrong: I let agents decide too much
The other mistake was letting agents drive too many fundamental decisions.
Agents are useful for implementation options. They can inspect code, propose tradeoffs, find edge cases, and write the boring parts. But the core product decisions still need to come from the human.
For this project, those decisions were things like:
- the agent is read-only research software, not a trading bot
- answers start from evidence, not vibes
- missing provider data should be visible instead of hidden
- layer ownership should stay explicit
- risk and uncertainty should be visible, not buried
- educational questions should not trigger fake current-data workflows
- evals should judge usefulness, not just tool usage
When I held those lines, agents were great. When I left them fuzzy, agents overbuilt. They added workflows when a better answer contract would do. They added prompt text when a router fixture was needed. They added UI states when the product probably needed a sharper no.
The hard part is not getting an agent to write code. The hard part is building a process that decides what code deserves to exist.
The loop I would reuse
If I started over, I would keep this workflow:
- Write the product invariant in plain language.
- Explore the idea with an agent until the shape is clear.
- Turn it into an OpenSpec proposal before implementation.
- Review the proposal or diff with a second agent.
- Give the implementation agent a small task against that spec.
- Require deterministic tests for the narrow behavior.
- Add or update an eval using a real user prompt.
- Run the app or harness and inspect the trace.
- For GUI changes, include build proof and screenshots.
- Keep docs and changelog in sync.
- Ask what can be deleted or simplified before merging.
That loop is slower than “agent, build feature.” It is much faster than cleaning up a codebase full of agent-shaped decisions.
Final take
The biggest lesson for me was that agents do not remove the need for product judgment. They move the bottleneck toward it.
OpenCandle was useful as a finance project because finance made the hidden parts of agent design hard to ignore. The system could not just sound confident. It had to know when to fetch evidence, which tools owned which facts, how to expose missing data, what uncertainty to preserve, and what kind of answer it was allowed to give. Those constraints are not finance-specific. They are what make a domain agent credible.
Building on Pi helped because the core loop stayed inspectable. Building with agents helped because I could move quickly across specs, tools, evals, UI, docs, and reviews. But speed was only valuable when the rails were clear. When the product invariant, answer contract, eval, or ownership boundary was vague, agents did what they are naturally good at: they added more code.
That is the trap of agent-built software. The code gets cheaper before the judgment gets better.
If I were taking one lesson into the next project, it would be this: use agents to accelerate implementation, exploration, review, and cleanup, but do not outsource the core decisions. Decide what the product is, what evidence counts, what failure looks like, what should stay visible to the user, and what should be deleted. Then let agents work inside those constraints.